1.2 Disaster Recovery Implementations
Stretch clusters and cluster-of-clusters are two approaches for making shared resources available across geographically distributed sites so that a second site can be called into action after one site fails. To use these approaches, you must first understand how the applications you use and the storage subsystems in your network deployment can determine whether a stretch cluster or cluster of clusters solution is possible for your environment.
1.2.2 Stretch Clusters versus Cluster of Clusters
A stretch cluster and a cluster of clusters are two clustering implementations that you can use with Novell Cluster Services to achieve your desired level of disaster recovery. This section describes each deployment type, then compares the capabilities of each.
Business Continuity Clustering automates some of the configuration and processes used in a cluster of clusters. For information, see Section 1.3, Business Continuity Clustering.
Stretch Clusters
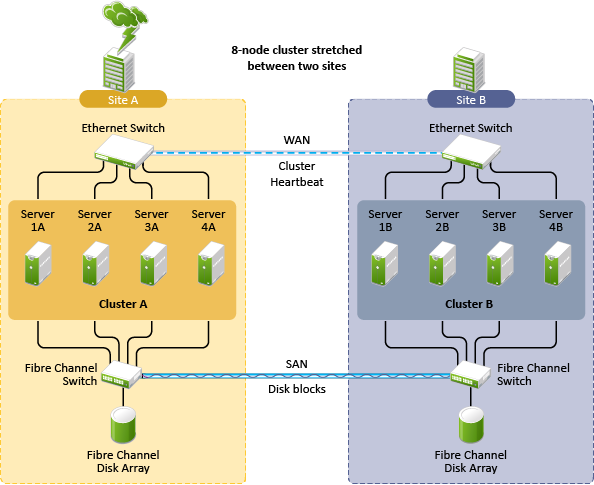
A stretch cluster consists of a single cluster where the nodes are located in two geographically separate data centers. All nodes in the cluster must be in the same eDirectory tree, which requires the eDirectory replica ring to span data centers. The IP addresses for nodes and cluster resources in the cluster must share a common IP subnet.
At least one storage system must reside in each data center. The data is replicated between locations by using host-based mirroring or storage-based mirroring. For information about using mirroring solutions for data replication, see Section 1.2.1, Host-Based versus Storage-Based Data Mirroring. Link latency can occur between nodes at different sites, so the heartbeat tolerance between nodes of the cluster must be increased to allow for the delay.
The split-brain detector (SBD) is mirrored between the sites. Failure of the site interconnect can result in LUNs becoming primary at both locations (split brain problem) if host-based mirroring is used.
In the stretch-cluster architecture shown in Figure 1-1, the data is mirrored between two data centers that are geographically separated. The server nodes in both data centers are part of one cluster, so that if a disaster occurs in one data center, the nodes in the other data center automatically take over.
Figure 1-1 Stretch Cluster
Cluster of Clusters
A cluster of clusters consists of multiple clusters in which each cluster is located in a geographically separate data center. Each cluster should be in different Organizational Unit (OU) containers in the same eDirectory tree. Each cluster can be in a different IP subnet.
A cluster of clusters provides the ability to fail over selected cluster resources or all cluster resources from one cluster to another cluster. For example, the cluster resources in one cluster can fail over to separate clusters by using a multiple-site fan-out failover approach. A given service can be provided by multiple clusters. Resource configurations are replicated to each peer cluster and synchronized manually. Failover between clusters requires manual management of the storage systems and the cluster.
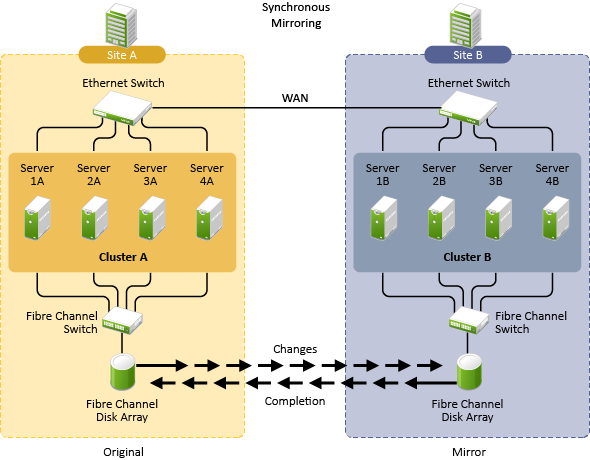
Nodes in each cluster access only the storage systems co-located in the same data center. Typically, data is replicated by using storage-based mirroring. Each cluster has its own SBD partition. The SBD partition is not mirrored across the sites, which minimizes the chance for a split-brain problem occurring when using host-based mirroring. For information about using mirroring solutions for data replication, see Section 1.2.1, Host-Based versus Storage-Based Data Mirroring.
In the cluster-of-clusters architecture shown in Figure 1-2, the data is synchronized by the SAN hardware between two data centers that are geographically separated. If a disaster occurs in one data center, the cluster in the other data center takes over.
Figure 1-2 Cluster of Clusters with Storage-Based Data Mirroring
Comparison of Stretch Clusters and Cluster of Clusters
Table 1-2 compares the capabilities of a stretch cluster and a cluster of clusters.
Table 1-2 Comparison of Stretch Cluster and Cluster of Clusters
|
Capability |
Stretch Cluster |
Cluster of Clusters |
|---|---|---|
|
Number of clusters |
One |
Two to four |
|
Number of geographically separated data centers |
Four |
Two to four |
|
eDirectory trees |
Single tree; requires the replica ring for the cluster to span data centers. |
Single tree |
|
eDirectory Organizational Units (OUs) |
Single OU container for all nodes. As a best practice, place the cluster container in an OU separate from the rest of the tree. |
Each cluster should be in a different OU. Each cluster is in a single OU container. As a best practice, place each cluster container in an OU separate from the rest of the tree. |
|
IP subnet |
IP addresses for nodes and cluster resources must be in a single IP subnet. Because the subnet spans multiple locations, you must ensure that your switches handle gratuitous ARP (Address Resolution Protocol). |
IP addresses in a given cluster are in a single IP subnet. Each cluster can use the same or different IP subnet. If you use the same subnet for all clusters in the cluster of clusters, you must ensure that your switches handle gratuitous ARP. |
|
SBD partition |
A single SBD is mirrored between four sites by using host-based mirroring, which limits the distance between data centers to 10 km. |
Each cluster has its own SBD. Each cluster can have an on-site mirror of its SBD for high availability. |
|
Failure of the site interconnect if using host-based mirroring |
LUNs might become primary at both locations (split brain problem). |
Clusters continue to function independently. |
|
Storage subsystem |
Each cluster accesses only the storage subsystem on its own site. |
Each cluster accesses only the storage subsystem on its own site. |
|
Data-block replication between sites For information about data replication solutions, see Section 1.2.1, Host-Based versus Storage-Based Data Mirroring. |
Yes; typically uses storage-based mirroring, but host-based mirroring is possible for distances up to 10 km. |
Yes; typically uses storage-based mirroring, but host-based mirroring is possible for distances up to 10 km. |
|
Cluster resource failover |
Automatic failover to assigned nodes at the other site. |
Automatic failover to preferred nodes on one or multiple clusters (multiple-site fan-out failover). Failover requires additional configuration. |
|
Cluster resource configurations |
Configured for a single cluster. |
Configured for the primary cluster that hosts the resource, then the configuration is manually replicated to the peer clusters. |
|
Cluster resource configuration synchronization |
Controlled by the master node. |
Manual process that can be tedious and error-prone. |
|
Failover of cluster resources between clusters |
Not applicable. |
Manual management of the storage systems and the cluster resources. |
|
Link latency between sites |
Can cause false failovers. The cluster heartbeat tolerance between master and slave must be increased to as high as 12 seconds. Monitor cluster heartbeat statistics, then tune down as needed. |
Each cluster functions independently in its own geographical site. |
|
Advantages |
|
|
|
Disadvantages |
|
|
|
Other Considerations |
|
|
Evaluating Disaster Recovery Implementations for Clusters
Table 1-2 examines why a cluster of cluster solution is less problematic to deploy than a stretch cluster solution. It identifies the advantages, disadvantages, and other considerations for each. Manual configuration is not a problem when using Business Continuity Clustering for your cluster of clusters.