The ULENGTH Function
The function type is integer.
General Format
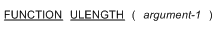
Arguments
- argument-1
- This must be alphabetic, alphanumeric, or UTF-8 and must contain valid UTF-8 encoded characters, or must be national and contain valid UTF-16 encoded characters.
Returned Values
The returned value is the number of UTF-8 or UTF-16 characters in argument-1.
Notes
If argument-1 is a national data item that contains UTF-16 data and argument-1 contains surrogate pairs, each pair of low and high surrogates will be counted as one UTF-16 character.
If the UTF-8 argument contains composed characters (for example, ä, ê, and ü), the combining characters are counted individually in determining the length. See the following example where the returned value may vary for a composed character:
| Character | Unicode encoding | UTF-8 encoding | Returned value |
|---|---|---|---|
| ä |
U+00E4 (precomposed form, Latin small letter a with diaeresis) |
x'C3A4' | 1 |
|
U+0061 + U+0308 (canonical decomposition, Latin small letter a + combining diaeresis) |
x'61CC88' | 2 |
Comments
This function supports ideographic variation selectors (IVS), allowing the font software to select a different glyph from the default. (If no variation exists or supported then the font software will ignore it.) An IVS consists of Unicode characters in the range U-E0100 – U-E01EF. UTF-16 strings use surrogate pairs in the range U-DB40 + DD00 - U-DB40 + DDEF, and UTF-8 strings use the range 0xF3A08480 - 0xF3A087AF.
A Unicode character followed by an IVS is treated as one character when this function is processed.