Viewing HSF Information as a .csv File
If you have enabled the collection and writing of HSF records to disk, details of individual transaction runs are written to comma-separated-values files, one HSF record per line.
These files are named cashsf-a.csv and cashsf-b.csv, and are located in the system directory. One of these file is the active file at any one time, and once the active file is full, or when you click the Switch button in the HSF Data section of the ESMAC Control page, records are written to the alternate file, until the maximum file size is reached or the Switch button is clicked again.
The .csv files produced in this version of the product have the following header, and contain the following fields:
#HSFVer=05;Custom=xx;CicsFiles=xx;TSQ=xx;TDQ=xx;SUBTASK_ID=yy Type,PID,Task,Date,Time,Tran/Job,User/DDName/CC,LU/Step,Prog/DSName,Latent/ReadCount,Resp/WriteCount, API/RewriteCount,SQL/DeleteCount,IMS/DSDeleteCount,DSType,DSAccessType,Custom01,File01,Count01,Time01,TS01,Count01,Time01,TD01,Count1,Time1
The number of Custom, File, TS and TD fields correspond to the xx values in the header, which are set according to the ES_HSF_CFG environment variable.
When setting the variable, values must be set within a permissible range, otherwise the default value is used for that field. Also, if the field name is not explicitly set within the variable, its default value is used. The ranges and defaults are:
| Field name | Range | Default |
|---|---|---|
| CUSTOM | 0-5 | 0 |
| TSQ | 0-20 | 5 |
| TDQ | 0-20 | 5 |
| SUBTASK | 00-FF | 00 |
For example: ES_HSF_CFG=CUSTOM=2;TSQ=32;SUBTASK=F1 generates 2 custom fields, , 5 TSQ fields, and 5 TDQ fields and trace id x’F1’ is used to generate SUBT records.
Field types
- Type
- WEB - for Web services
- PID
- Process ID of the SEP which ran the task.
- Task
- A unique task number.
- Date
- The date the task started to run, in the format yyyymmdd.
- Time
- The time the task started to run, in the format hhmmssttt (where ttt denotes thousandths of a second).
- Tran/Job
- The Web service name
- Latent/ReadCount
-
- The time, in milliseconds (ms), between Enterprise Server receiving the request and the task beginning to run.
- Resp/WriteCount
-
- The time, in milliseconds (ms), that the task ran for (not including latency time).
- SQL/DeleteCount
-
- The time spent, in milliseconds (ms), in SQL API (EXEC SQL statements) for this task.
- CPU Time
- Amount of CPU time, in milliseconds (ms), the task used1.
- Mem Usage
- Amount of memory usage, in kilobytes (kB)1.
- IO Read Size
- Amount of data read, in kilobytes (kB)1.
- IO Write Size
- Amount of data written, in kilobytes (kB)1.
- IO Read Count
- Number of read system calls1.
- IO Write Count
- Number of write system calls1.
- MQ Time
- Time spent, in milliseconds (ms), making MQ API calls1.
- EZASOKET Time
- Time spent, in milliseconds (ms), making EZASOKET API calls1.
- DSType
- This field is blank for all records.
- DSAccessType
- This field is blank for all records.
| 1 These fields will only contain values if the region is configured to output them. This can be controlled by setting the environment
variable ES_HSF_RTS_MONITOR to ON or OFF.
On Linux, support for these fields is enabled by default. To disable them, set ES_HSF_RTS_MONITOR=OFF. On UNIX, these fields are not supported. |
Configurable Field Types
The following additional fields may be repeated based on the value of the ES_HSF_CFG environment variable:
- Customxx
- Custom data written to the record via a call to ES_WRITE_CUSTOM_HSF from the user application.
- Filexx
- The name of a file that the transaction accessed.
-
- Countxx
- The number of times the transaction accessed this filexx.
- Timexx
- The time, in milliseconds (ms), the transaction spent accessing filexx.
- TSxx
- The name of a temporary storage queue (TSQ) that the transaction accessed.
-
- Countxx
- The number of times the transaction accessed TSxx.
- Timexx
- The time, in milliseconds (ms), the transaction spent accessing TSxx.
Sample content viewed in Microsoft Excel
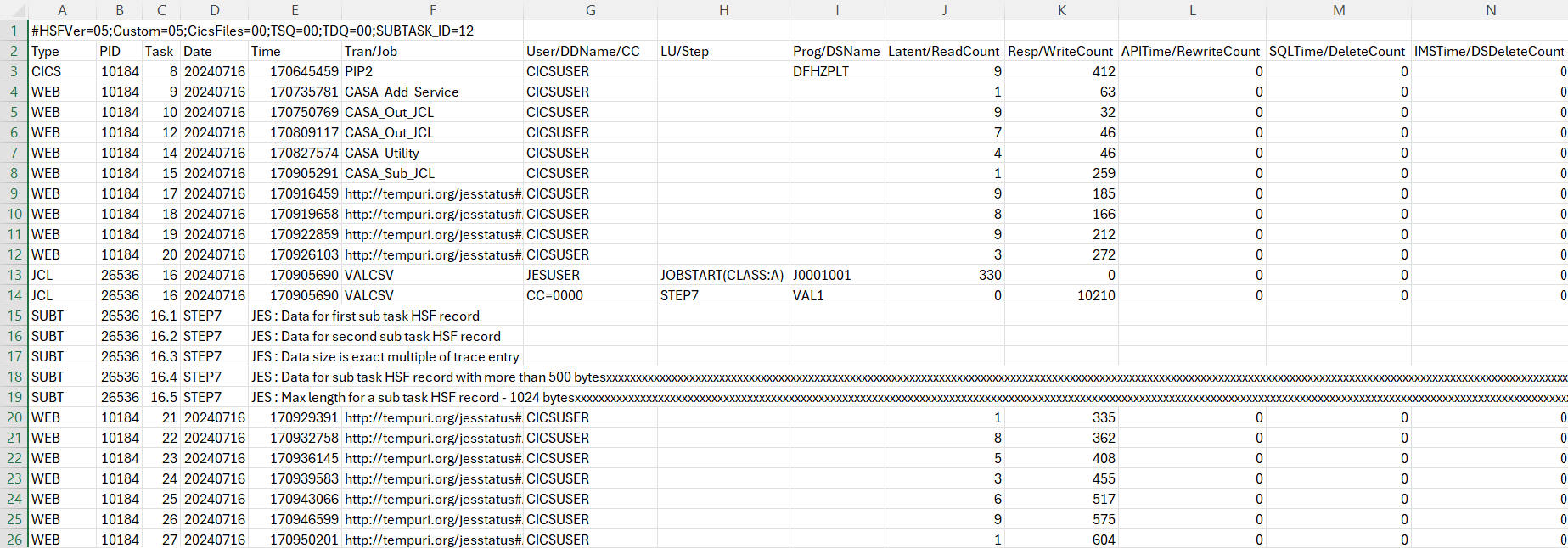
SUBT Type
The format for SUBT types is as follows:
"SUBT",PID,Task.Seq,Trans-id/job step,Custom data
For example:
SUBT,1234,12.1,HSF1,My data
"Custom data" is written in the same way as for custom fields, that is, by calling ES_WRITE_CUSTOM_HSF or ESCSTHSF with a 1 byte trace ID.
For sub task records, only a single ID can be used. Every call to ES_WRITE_CUSTOM_HSF/ESCSTHSF with that ID will result in a new SUBT record being generated. Custom data for these records can be up to 1024 bytes in length.
To configure this feature, the value for the ES_HSF_CFG environment variable needs to contain SUBTASK=ID where ID is the unpacked hex ID that will identify traces that will be used to generate the SUBT records. Valid values are 01 - FF. If ES_HSF_CFG does not contain a SUBTASK or if SUBTASK=00 then the feature is switched off.
For example, setting the following:
ES_HSF_CFG=SUBTASK=1A
would require a call to ES_WRITE_CUSTOM_HSF/ESCSTHSF using an ID of H"1A" in order to generate a SUBT record.