 ).
). This chapter provides an overview of the Open PL/I language, explaining the following basic concepts:
Open PL/I is a block-structured language. Each block consists of a group of statements. Statements are used to declare constants and variables, and to express actions to be performed by your program. For example:
READ FILE (G) INTO (Y) ;
In this example, the READ statement reads the next record in file G into storage Y.
Each Open PL/I statement consists of a series of elements ending with a semicolon. These elements can be PL/I keywords, user-specified identifiers, literal constants, or punctuation symbols.
A name used to denote part of a statement such as a verb, option, or clause, is called a keyword. All statements, except the assignment statement, begin with a keyword that identifies the purpose of the statement. In the previous example, READ, FILE, and INTO are keywords.
GOTO L; CALL S(B,C,D); RETURN; STOP; DO K = 1 TO 11; TO = 20; /* ASSIGNMENT STATEMENT*/
There are no reserved words in Open PL/I. For instance, in the last example, TO names a storage location.
A name is also used to denote an object operated upon by the program, such as a variable, file, or label. These names are known as identifiers. Their meanings are established by a declaration. In the example given previously,
READ FILE (G) INTO (Y) ;
G and Y are identifiers.
The following examples show how names can be used either to establish an object to be operated on or to denote part of a statement.
DECLARE X(5) FIXED; L: X(3) = 25;
In the previous examples, both X and L are identifiers, but DECLARE and FIXED are keywords. X is declared by a DECLARE statement; L is implicitly declared as a label.
A name consists of any combination of the following:
The following rules apply for the creation of names.
STREET_NAME @BETA #Y7 C $7
Names can be written using both uppercase and lowercase letters.
By default, all lowercase letters are interpreted as their uppercase equivalents. The -lowercase compiler option causes the reverse of this behavior. Refer to the Open PL/I User's Guide for more information on this option.
There are no reserved names in Open PL/I; names that are used as keywords, such as READ or INTO, can also be identifiers. However, this practice makes programs difficult to read and should be avoided whenever possible.
The meaning of a name is normally determined by its declaration. However, in some cases a name can be implicitly declared by the context in which it is used. (For more information, see the sections Compiler-supplied Defaults and The Default Statement.) The declaration of a name consists of a user-specified identifier and the attributes of that name.
Open PL/I permits two kinds of explicit declarations: the DECLARE statement and the label prefix.
The DECLARE statement declares the names of files, variables, and external procedures. A DECLARE statement can appear anywhere within the program, except as part of a compound statement. Regardless of where it appears, DECLARE is not an executable statement and has no effect except to establish the meaning of names.
DECLARE F FILE; DECLARE A(5) FLOAT; DECLARE (I,J,K) FIXED BINARY(15);
In the previous examples, F is declared as the name of a file constant; A is declared as a floating-point array variable; and I, J, and K are declared as integer variables.
A label, also called a label prefix, is a user-specified identifier that names a statement so that it can be referenced elsewhere in your program. The label comes before the statement and is terminated with a colon (:).
F: FORMAT(F(8,2),A(5)); P: PROCEDURE; L: READ FILE(F) INTO(X);
In these examples, F is declared as a format name, P as a procedure name, and L as a statement label.
Labels can appear on all Open PL/I statements except target statements of ON statements (called ON-units as described in the section ON Statement), ELSE or THEN clauses in IF statements, and WHEN or OTHERWISE clauses in SELECT statements.
Use of a name in any context, other than in a declaration, constitutes a reference to the name. To determine the meaning of the reference, the Compiler searches for a declaration of the name. This search resolves the reference by associating it with a declaration. For example:
DECLARE A FIXED BINARY(15); DECLARE B FLOAT; B = B+1; A = A+1;
In the previous example, the Compiler knows that it must generate a floating-point add for B+1 because it has resolved the reference B to the second DECLARE statement. Likewise, it knows that it must generate an integer add for A+1 because it has resolved the reference A to the first DECLARE statement. For more information on reference resolution, see the section Reference Resolution.
A constant is a sequence of characters that represents a particular, unchanging value. In Open PL/I, four kinds of constants are permissible:
These are actual numbers or strings written in the source program. Literal constants are restricted to character strings, bit strings, and fixed- or floating-point numbers.
These are established using a label prefix in the source program that declares a name either as the name of a format or a procedure, or as a statement label.
These constants are typically established by DECLARE statements. File constants are identifiers declared with the FILE attribute to describe the type of input/output to be performed on a file. Entry constants are used to invoke procedures at certain entry points.
These are identifiers that are to be changed with the %REPLACE statement. Like literal constants, constant identifiers can also be character strings, bit strings, and fixed- or floating-point decimal numbers. For more information on %REPLACE, see the section Text Replacement and Insertion Statements.
| Constant | Type |
|---|---|
| 25 | Integer constant |
| 7.5 | Fixed-point decimal constant |
| 3.12E-01 | Floating-point decimal constant |
| 'How are you?' | Character-string constant |
| '1'B | Bit-string constant (binary notation) |
| '1011'B | Bit-string constant (binary notation) |
| '775'B3 | Bit-string constant (octal notation) |
| 'A7O'B4 | Bit-string constant (hexadecimal notation) |
| STARTUPD: | Label constant |
| %REPLACE TABLE_SIZE BY 350; | TABLE_SIZE is an identifier to be replaced by an integer constant |
| DECLARE E ENTRY; | E is an entry constant |
| DECLARE F FILE; | F is a file constant |
For a table showing the expansion of nonbinary notation into binary notation, see the section Bit-String Data.
Arithmetic constants represent decimal values, whereas binary arithmetic values have no constant representation. Nevertheless, any decimal constant can be converted easily to a binary value by using it in a context that expects a binary arithmetic value.
As a result of Open PL/I language rules, all constants that appear as floating-point numbers in a source program are actually of type float decimal and are subject to the rules of float decimal arithmetic.
A character-string constant can contain any character, except that, if an apostrophe is required within a character-string constant, it is written as two apostrophes. For example,
'He said, "I''m fine."'
Note: The double quotation mark character is not equivalent to a single quotation mark or two adjacent single quotation marks and has no more significance than any other character within a constant.
In Open PL/I, the maximum size of a string constant is 256 characters or bits (for details, see the section Open PL/I Compiler Implementation Limits in the chapter Using Open PL/I of your Open PL/I User's Guide ). The Compiler checks this limit after bit-string constants written in the B2, B3, or B4 format (described in the section B-Format) have been expanded. Refer to the data type descriptions in the chapter Language Specifics of your Open PL/I User's Guide for the maximum size limits for floating- and fixed-point data.
In Open PL/I, punctuation symbols are either operators or separators.
Operators define the arithmetic or comparative operations to be performed on expressions in a statement. Table 1-1 lists the Open PL/I operators.
| Symbol | Meaning |
|---|---|
| + | Addition or the plus prefix |
| - | Subtraction or the minus prefix |
| * | Multiplication |
| ** | Exponentiation |
| / | Division |
| ^ or ~ | Logical NOT |
| | or ! | Logical OR |
| & | Logical AND |
| > | Greater than |
| < | Less than |
| = | Equal to |
| ^> or –> | Not greater than |
| ^< or –< | Not less than |
| ^= or ~= | Not equal to |
| >= | Greater than or equal to |
| <= | Less than or equal to |
| || or !! | String concatenation |
| –> | Pointer resolution |
Separators delimit and separate identifiers, keywords, and constants in statements. Table 1-2 lists the Open PL/I separators.
| Symbol | |
|---|---|
| Meaning | |
| ( ) | Encloses lists, defines order of expression evaluation, separates names of statements and options from specific keywords |
| , (comma) | Separates subscripts and procedure arguments, separates identifiers in a structure name, and precedes the BY NAME option |
| ' (single quote) | Delimits bit strings and character strings |
| . (period) | Specifies a decimal point. Connects elements of a qualified name |
| : | Terminates a procedure name or a statement label |
| ; | Delimits statements |
Names and constants may be separated from one another by one or more blanks, or tabs, rather than by separators. Additional blanks surrounding punctuation symbols are optional. In the following examples, blanks are represented by boxes ().

The first statement requires no blanks because each name is separated from the next by a punctuation symbol. The second statement shows the optional use of extra blanks. The third statement shows optional blanks surrounding the equal symbol (=) and after the semicolon, the remaining blanks being required blanks.
Note that when an arithmetic constant is followed by a name, at least one blank or punctuation symbol is required to separate the arithmetic constant from the name.
Comments are used to document an Open PL/I program. A comment can appear anywhere that a blank can appear and is equivalent to a blank. Comments cannot be nested. The general form of a comment is:
/*Comments open with a slash* and close with a *slash */
For example,
/*HERE IS A COMMENT*/ IF A<25 /* HERE IS ANOTHER ONE */ THEN /*HERE IS AN /* ERRONEOUS */ COMMENT */
The final comment is invalid because comments cannot be nested; it ends at the first * / in the line and the Compiler attempts to interpret COMMENT */ as code and produces an error message.
The Compiler puts an asterisk (*) into the line number field of the listing file for each line on which a comment is continued from a preceding line. This convention can be used to determine if some text was accidentally included in a comment.
Comments can continue over any number of lines of program text; thus, if the */ is omitted from a comment, all program text up to the next */ is considered part of the comment. This causes part of the program to be ignored by the Compiler and may cause it to produce misleading error messages. The same problem occurs if a character-string or bit-string constant is not terminated with an apostrophe.
This section introduces certain Open PL/I statements that, alone or in conjunction with other statements, provide specific capabilities within Open PL/I. Each of the statements discussed in this section is also discussed individually in more detail in the chapter Statements.
Open PL/I has four compound statements:
IF, ON, DO, and SELECT are called compound statements because they each contain other statements.
The IF statement tests an expression and performs a specified action if the result of the expression is true. Its general form is:
IF expression THEN statement; [ELSE statement];
where expression is any valid expression that yields a scalar bit-string value, and statement is any unlabeled statement (except DECLARE, END, ENTRY, FORMAT, or PROCEDURE) or an unlabeled DO-group or BEGIN block. For example:
IF A>B
THEN READ FILE (F) INTO (X);
In this example, the IF statement contains the READ statement. If the expression A>B is true, the READ statement executes.
The IF statement needs no semicolon of its own because each statement contained within it has its own semicolon. IF statements can be nested, as shown in the following example.
IF A>B
THEN IF D<C
THEN READ FILE(F) INTO(X);
ELSE STOP;
In this example, the second IF statement has both a THEN clause and an ELSE clause. An ELSE clause always corresponds to the THEN clause that immediately precedes it. The first IF statement has only a THEN clause. If you want to STOP when A ^> B, you may provide a null ELSE clause to the innermost IF, forcing the ELSE STOP to be associated with the first IF. It is preferable to use structured IF, THEN, and DO statements to accomplish this, as shown in the following example.
IF A>B THEN DO;
IF D<C THEN READ FILE(F) INTO (X);
END;
ELSE STOP;
The ON statement defines the action to be taken when a specific condition is signaled during the execution of a program. Its general form is:
ON condition–name ON-unit,
or
ON condition–name SYSTEM
where:
condition-name is ANYCONDITION, AREA, ATTENTION, CONDITION(name), CONVERSION, ENDFILE(f), ENDPAGE(f), ERROR, FINISH, KEY(f), OVERFLOW, RECORD(f), UNDEFINEDFILE(f), UNDER- FLOW, USERCONDITION(expression), USERCONDITION(SS$_UNWIND), or ZERODIVIDE.
ON-unit is a BEGIN block or any statement other than DECLARE, DEFAULT, DO, END, ENTRY, FORMAT, LEAVE, OTHERWISE, PROCEDURE, RETURN, or SELECT.
The keyword SYSTEM indicates that, instead of executing user-specified code in the ON-unit, a system-generated message describing the condition is displayed and the ERROR condition is signaled. For example:
ON ENDFILE (F )
BEGIN;
.
.
.
END;
In this example, the block of statements between the BEGIN and END statement executes if the end-of-file condition is reached.
ON is a compound statement, but it cannot be nested. The ON statement's use in responding to exceptional conditions is explained more fully in the section Statement that Handles Exception Conditions.
The DO statement begins a sequence of statements to be executed in a group, called a DO-group. Its general form is:
DO; . . . END;
For example:
IF B < C THEN DO;
PUT LIST ('ADDED DATA REQUIRED');
GET LIST (VALUE);
B = B + VALUE;
END;
In this example, the PUT LIST, GET LIST, and assignment statements execute if B < C.
DO statements can contain IF statements, other DO-groups, RETURN statements, or GOTO statements that alter the order of execution.
The SELECT statement tests a series of expressions and performs the action specified with the first true test, or the action associated with the OTHERWISE clause (if present) and none of the tests evaluates true. Its general form is:
SELECT[select-expression];
WHEN (e1[,e2[,e3[...]]]) action_1; WHEN (e4[,e5[,e6[...]]]) action_2; . . . [OTHERWISE action_m;] END;
where select-expression and e1, e2... are valid expressions, and each action is a single or compound statement or a BEGIN block. For example:
SELECT;
WHEN (F=40) G=G+1;
WHEN (F=50) IF G > 0 THEN G=G+2;
.
.
.
OTHERWISE DO;
.
.
.
END;
END;
This example shows the SELECT statement used with the expression omitted. When the expression is omitted from the SELECT statement, each WHEN clause expression is evaluated and converted, if necessary, to a bit string. The action after the WHEN clause is performed if the resulting bit string is nonzero. In the above example, if F=40 is true, the action G=G+1 is executed and the SELECT group is exited. If F=50 is true, the IF statement is executed and the SELECT group is exited. If more than one WHEN statement is true, the action associated with the first true WHEN clause is executed. If no WHEN clauses are true, the DO group associated with the OTHERWISE clause is executed.
When control reaches a SELECT statement with a select–expression present, the select-expression is evaluated and its value saved. Next, the expressions in the WHEN clauses are evaluated in the order in which they appear, and each value is compared with the value of select–expression. If a value is found that is equal to the value of select–expression, the action following the corresponding WHEN clause is performed, and no further WHEN clause expressions are evaluated. If none of the expressions in the WHEN clauses is equal to the select–expression, the action specified after the OTHERWISE clause is executed unconditionally. for more information, see the section SELECT Statement.
Statements are typically executed in the order in which they are written; however, certain statements control the order of execution of the program. These statements are GOTO (used with a statement label), IF, and DO.
The GOTO statement causes control to be transferred to a labeled statement in the current procedure or in another active procedure. Its general form is:
GOTO label–reference[OTHERWISE];
or
GO TO label–reference[OTHERWISE];
where:
label–reference is a label constant or an expression that, when evaluated, yields a label value. (A label value denotes a statement in the program.) For example:
A = 5;
GOTO L2;
L1:
B = 7;
.
.
.
L2:
B = 4;
In this example, A is assigned 5 and B is assigned 4. The statements beginning with label L1 can be executed only if a GOTO statement transfers control to the label L1.
Although labels are a convenient means to represent a specific location in a program, programs that contain many labels are generally more difficult to read and modify. The use of labels and GOTOs can be avoided or minimized by using the compound statements IF and DO to control the order of statement execution.
The DO statement causes all statements between the DO statement and its corresponding END statement to be executed a number of times as determined by the form of the DO statement.
The ON statement gives your Open PL/I programs the ability to respond to exception conditions that occur during the execution of a program, such as end-of-file, or computational errors such as division by zero. For example:
ON ERROR
BEGIN;
.
.
.
END;
Execution of the ON statement establishes the ON-unit as a block of statements that are executed if the specified condition occurs. If the specified condition occurs after the ON statement is executed, processing is interrupted and the specified ON–unit is executed. In the above example, the block of statements between the BEGIN and END statements are established as the ON–unit, which executes if the ERROR condition occurs. Execution of the ON statement does not cause immediate execution of the ON-unit.
An ON-unit is established within its containing block's current activation and remains established until that block returns to its caller, or until another ON-unit is established for the same condition within the same block activation, or until the ON-unit is reverted using the REVERT statement.
If one of the possible conditions occurs during the execution of a block, and that block does not have an established ON-unit for that condition, the calling block's ON-unit is used to respond to the condition. If the calling block has no established ON-unit for the condition, its caller's ON-unit is used, and so on. If no ancestor has an ON-unit for the condition, a default action is taken. Except for the ENDPAGE, FINISH, and UNDERFLOW conditions, this default action ends program execution and issues a run-time error message.
ON-units for the ERROR condition cannot resume execution of the statement in which the error was detected.
When a program module is being compiled, the Compiler is able to recognize and evaluate two statements that alter the program text: %INCLUDE and %REPLACE. Both of these statements can be used anywhere within a procedure or source file to simplify the job of writing programs.
Other statements that alter program text are described in the appendix Open PL/I Macro Preprocessor.
The %INCLUDE statement incorporates text from other files into the current source file during compilation. The general form of this statement is:
%INCLUDE filename[,filename]...;
where:
filename is one of the following:
The specified filename is used to locate a text file whose content is inserted into the program text in place of the %INCLUDE statement.
Your selection of one of these forms in combination with the presence or absence of the -ipath compiler option affects the search pattern used in locating files to be included. For more information, see the section %INCLUDE Statement.
Note: The Open PL/I Macro Preprocessor has its own %INCLUDE statement. Its use is documented in the appendix Open PL/I Macro Preprocessor.
The %REPLACE statement specifies that an identifier is to be replaced by a specified constant or other name during compilation. The general form of this statement is:
%REPLACE name BY constant-or-name;
Beginning at the point at which the %REPLACE statement is encountered, each occurrence of name that follows the %REPLACE statement is replaced by the specified constant or other name until the end of compilation.
The %REPLACE statement is often used to supply the sizes of tables or to give names to special constants whose meaning would not otherwise be obvious. For example:
%REPLACE TRUE BY '1'B;
%REPLACE TABLE_SIZE BY 400;
%REPLACE MOTOR_POOL BY 5;
%REPLACE X BY -3.0E0;
DECLARE X(TABLE_SIZE) FIXED STATIC;
DO K = 1 TO TABLE_SIZE;
IF DEPARTMENT_NUMBER = MOTOR_POOL
THEN DO;
.
.
.
Both the %REPLACE and %INCLUDE statements operate on the program text without regard to the meaning of the text.
The %REPLACE statement substitutes all subsequent occurrences of the name without regard to the block structure of the module, as explained in the section Blocks.
One or more external procedures can be present within a single Open PL/I source file. All external procedures within a source file will be compiled by the Compiler into a single object file.
A module is defined as a single compilation unit, a source file that is compiled into object code. A module consists of one or more external procedures.
A source file may contain declarations that appear outside the scope of any external procedure, as long as all variables that appear in such declarations are BASED, STATIC, or DEFINED. A variable that is defined this way is known within the scope of all external procedures. If a declaration is provided with the EXTERNAL attribute, it will be known outside the source file.
A source file may also contain %REPLACE statements and declarations of named constants (for example, file and entry constants) before the first external procedure.
The following example illustrates a source file that has declarations and %REPLACE statements preceding the first external procedure. There are two procedures (GETREC and PUTREC) in the source file that can be used as part of the program. By default, Open PL/I declares these entry constants, GETREC and PUTREC, with the EXTERNAL attribute; therefore, a procedure from another module outside of this source file can invoke GETREC or PUTREC. If a procedure in another module needs to reference GETREC and PUTREC, they must be declared within that module with the attributes ENTRY and EXTERNAL.
At the top of this source file are other items (REC, NAME, ADDRESS) that are hidden from any procedures compiled in other modules, and are known only to GETREC and PUTREC. Because Open PL/I, by default, provides file constant declarations with the EXTERNAL attribute, the file DATA_BASE can be known in other modules.
%REPLACE DATA_SIZE BY 80;
DECLARE 1 REC BASED
2 NAME CHAR(40),
2 ADDRESS CHAR(DATA_SIZE);
DECLARE DATA_BASE KEYED FILE UPDATE;
GETREC: PROCEDURE(P);
DECLARE P POINTER;
READ FILE(DATA_BASE) INTO(P->REC);
END GETREC;
PUTREC: PROCEDURE(P);
DECLARE P POINTER;
REWRITE FILE(DATA_BASE) FROM(P->REC);
END PUTREC;
PL/I is a block-structured language. Just as certain language elements make up statements, groups of statements make up blocks. Two types of blocks exist in Open PL/I:
A procedure block is the basic executable program unit of Open PL/I and is made up of a group of statements contained within the limits of a pair of statements, PROCEDURE and END.
A BEGIN block is a program unit into which control flows during the typical execution of a procedure. The statements within a BEGIN block are contained within the limits of a pair of statements, BEGIN and END.
Whenever a procedure block or BEGIN block is entered, a block activation is created for that block. The block activation consists of the allocation of storage for the variables declared within the block and the system information that links that block to the previous block in the activation chain.
The following sections provide detailed information on procedure and BEGIN blocks and activation of these blocks.
A procedure is a sequence of statements beginning with a PROCEDURE statement and ending with an END statement. The purpose of a procedure is to "package" a set of executable statements and declarations to form a block that can be executed from several places in the program simply by calling it. Because a procedure defines a block of statements, it is typically called a procedure block. The following example shows two procedure blocks, A and B:
A: PROCEDURE;
.
.
.
END A;
B: PROCEDURE;
.
.
.
END B;
Procedures contained within other procedures are called nested or internal procedures. Procedures not contained within other procedures are called external procedures. A program module consists of one or more external procedures. For example:
A: PROCEDURE;
.
.
.
B: PROCEDURE;
.
.
.
END B;
C: PROCEDURE
.
.
.
D: PROCEDURE;
.
.
.
END D;
END C;
END A;
In this example, Procedure A is external, and procedures B and C are nested within it. Procedure D is nested within procedure C.
Each procedure block establishes a distinct region of the program text called "scope," throughout which the names declared within that procedure block are known. The scope of a name is defined as the region of the program in which the name has meaning and can be referenced.
The scope of a name includes the procedure in which the name is declared and all procedures contained within that procedure, except those contained procedures in which the same name is redeclared. For example:
A: PROCEDURE;
DECLARE (X,Y) FLOAT;
.
.
.
B: PROCEDURE;
DECLARE X FILE;
DECLARE Z FIXED;
.
.
.
END B;
END A;
In this example, the scope of Y includes both procedure A and procedure B. The scope of X as a float is only procedure A. The scope of X as a file is procedure B. The scope of Z is procedure B. Z cannot be referenced from within procedure A. The scope of the procedure name B includes both procedure A and procedure B.
Statements within a procedure block are executed only when the procedure block is called from another procedure block. The CALL statement enables procedure calling. For example:
A: PROCEDURE;
.
.
.
CALL B;
.
.
.
B: PROCEDURE;
.
.
.
END B;
.
.
.
END A;
In this example, procedure B is executed only when it is called from procedure A. Procedure A resumes execution at the statement following the call when B is completed.
A procedure returns to its caller either by executing its END statement or by executing a RETURN statement, as shown in the following example:
A: PROCEDURE;
.
.
.
IF X<0 THEN RETURN;
.
.
.
END A;
Control does not "flow" into a procedure; that is, if control reaches a statement immediately preceding a procedure declaration, then (unless the statement is a control-flow statement such as GOTO) control will automatically skip to the statement following the declared procedure.
The usefulness of a procedure block is increased greatly if it can be made to operate on different values each time it is called. Arguments and parameters enable such operation.
Arguments are the values passed to a procedure block at invocation. Parameters are the names used by the invoked procedure block to refer to these arguments.
Open PL/I typically passes an argument to an invoked procedure by referencing its storage address.
For example:
CALL P(A,B);
.
.
.
CALL P(D,E);
.
.
.
P: PROCEDURE(X,Y);
.
.
.
PUT FILE (F) LIST(X,Y);
.
.
.
END P;
In this example, A and B are arguments of the first call to the procedure P. While P is executing as a result of the first call, the argument A is said to correspond to the parameter X and the argument B corresponds to the parameter Y. While P is executing as a result of the second call, D corresponds to X and E corresponds to Y.
When an argument is a variable, the actual address of the variable is passed to the called procedure. This allows the invoked procedure to change the value of the argument.
When an argument is a constant or an expression, a temporary location is used to store the current value of the argument, and the address of that temporary location is passed to the called procedure.
Each time a procedure block is called, it is said to be active, and it remains active until it returns from the call (or until a non-local GOTO transfers control to a containing block activation). Such procedure activation has an associated block of storage allocated on a stack. This block of storage is called a stack frame, and it is used to hold information (such as the location to which control should return from the activation) that is unique to each procedure activation.
The stack frame contains storage for the automatic data declared within the block. Thus, each activation of the block has its own copy of the automatic data.
If procedure A calls procedure B, the stack frame associated with the activation of A is pushed down by the stack frame associated with the activation of B. When B returns, its stack frame is popped from the stack and the stack frame of A is then the current stack frame.
If procedure A calls itself directly or indirectly by invoking a chain of procedures in which A is again called, A is said to be a recursive procedure. For example:
A: PROCEDURE RECURSIVE;
.
.
.
CALL A;
.
.
.
END A;
The following example shows a program that makes a copy of a tree structure using block activation and recursion principles.
.
.
NEW = COPY(OLD);
.
.
COPY: PROCEDURE(IN) RETURNS(POINTER)| RECURSIVE;
DECLARE (IN,OUT) POINTER;
DECLARE 1 RECORD BASED,
2 FIELD1 FLOAT,
2 FIELD2 FLOAT,
2 DAUGHTER POINTER,
2 SON POINTER;
DECLARE NULL BUILTIN;
IF IN = NULL THEN RETURN(NULL);
ALLOCATE RECORD SET(OUT);
OUT->RECORD.FIELD1 = IN->RECORD.FIELD1;
OUT->RECORD.FIELD2 = IN->RECORD.FIELD2; OUT->RECORD.DAUGHTER =
COPY(IN->RECORD.DAUGHTER);
OUT->RECORD.SON = COPY(IN->RECORD.SON);
RETURN(OUT);
END COPY;
As demonstrated in this example, each record of the original tree structure may be linked using pointers to a SON record and/or a DAUGHTER record. Either the SON or the DAUGHTER field may contain a null pointer value. COPY is called with a pointer to the root in the original tree structure. It returns a pointer to the root in a new tree structure that is a copy of the original. Each activation of the COPY procedure has its own instance of the variables IN and OUT.
For additional information about recursive procedures, see the section Entry Data.
Procedures are a natural division of the program and therefore provide the best mechanism to represent program modularity. The program should be organized or structured as a set of modules, each of which is written as a procedure.
Adhere to the following guidelines when using procedures:
A BEGIN block is a sequence of Open PL/I statements into which control flows during the routine execution of a program. A BEGIN block differs from a procedure in that it is invoked by executing its BEGIN statement, it cannot have any parameters, and it always returns by executing its END statement. In addition, execution of a RETURN statement within a BEGIN block returns to the caller of the procedure that immediately contains the BEGIN block. And, unlike a procedure, a BEGIN block can be used as the ON–unit of an ON statement.
The BEGIN block groups a set of program statements and defines a scope for the names declared within it. Generally, the reason for using a BEGIN block is to create a new scope and/or a new block activation. BEGIN blocks can contain DO-groups, SELECT groups, DECLARE statements, and procedures, as well as other BEGIN blocks.
The statements of a BEGIN block are bounded by BEGIN and END statements, as shown in the following example:
BEGIN; . . . END;
Since the BEGIN block contains declarations and ON-units, as well as executable statements, it can be used to permit temporary redefinitions of names and exception handlers, as well as to provide a means of allocating and freeing AUTOMATIC variables within it. (For additional information about AUTOMATIC variables, see the section Storage Classes.) For example:
DECLARE SUM FIXED BINARY; . . . BEGIN; DECLARE SUM FILE; DECLARE X(1000) FLOAT; . . . END;
In this example, SUM is redeclared within the BEGIN block so that it can be used as a file. A large array X is declared within the BEGIN block and is allocated storage only during the execution of the BEGIN block.
A variable is a named object that is capable of holding values. Each variable has two properties:
| Property | Description |
|---|---|
| Data type | Determines the kind of values a variable holds |
| Storage class | Determines the duration of a variable's existence and how it is referenced |
Each variable must be declared to have a data type. Except for cases under control of the DEFAULT statement, failure to specify a data type causes the Compiler to issue a warning and to give the variable a data type of Fixed Binary(15) if its name begins with any of the letters I through N; otherwise, the variable is given a data type of Float Decimal(6).
A complete discussion of data types is contained in the chapter Data Types. The following examples show several data types available in Open PL/I.
DECLARE A FLOAT DECIMAL(7); DECLARE N FIXED BINARY(15); DECLARE C CHARACTER(30); DECLARE B BIT(1);
In these examples, variable A is capable of holding any floating-point decimal value with mantissa of up to 7 digits and exponent of up to 3 digits; variable N is capable of holding any binary integer value between -32768 and +32767 inclusive; variable C is capable of holding any string of 30 characters; and variable B is capable of holding either '1'B or '0'B.
Although each variable is capable of holding values of only a specific data type, the Open PL/I language provides a complete set of operations that convert values from one data type to another. Whenever a value is assigned to a variable, it is first converted to the data type of the variable, as illustrated in the following examples (which refer to the declarations in the previous examples).
A = 1; /* converts 1 to FLOAT DECIMAL(7) */ N = 2.5; /* converts 2.5 to the FIXED BIN(15) integer 2 */ C = -4.5; /* converts -4.5 to a character string */ B = 0; /* converts integer 0 to '0'B */
For a complete discussion of data type conversions, see the chapter Data Type Conversions.
A variable's storage class determines when and for how long storage is to be allocated for the variable. Since this storage holds the variable's value, the storage class of a variable determines how long the variable retains its value.
The Open PL/I language permits the following six storage classes, which are fully explained in the chapter Storage Classes.
Unless declared otherwise, a variable's storage class is AUTOMATIC, meaning that it is allocated storage each time its immediately enclosing scope becomes active (as happens during a procedure call or the execution of a BEGIN statement. Exiting the scope frees this allocated storage (as happens at procedure or BEGIN block termination). Consequently, AUTOMATIC variables do not retain their values after deactivation of the block in which they are contained.
If a variable must retain its value between calls of its containing procedure, it should be declared to have the STATIC storage class. For example:
DECLARE K FIXED BINARY STATIC;
DECLARE TABLE(4) CHARACTER(5)
STATIC INITIAL('A','B','C','D');
In this example, each element of the array TABLE is given an initial value.
Storage for STATIC variables is allocated prior to program execution by the Compiler and linker. Consequently, the length (precision) of each STATIC variable must be constant at compile time.
In Open PL/I, a file is a source of input data or a target for data output. Files are referenced in I/O statements by using a file name declared with the FILE attribute. The file reference actually refers to a file constant or to a file variable that has been assigned a value.
Each file used by the program must be declared in exactly one module in the program. That module must either declare the file with the GLOBALDEF attribute or must be compiled with the -defext option.
A file constant is an identifier declared with the FILE attribute and without the VARIABLE attribute. For example:
DECLARE F FILE;
In this example, F is the name of a file constant.
A file constant cannot be the target of an assignment operation, and is external, by default. (For a discussion of assignment statements, see the chapter Statements.)
Each file constant is associated with a block of static storage called a file control block. The file control block retains information about the current status of the file while the file is open. In effect, the file constant is a pointer to, or a designator of, a file control block. File constants require the use of the -defext compiler option.
Each file control block's file identifier (ID) is the NAME of its associated file constant. The file ID in the previous example is F. This ID is used as the default TITLE of the file when it is being opened.
A file variable is a variable that can be assigned file values. A file variable can be given a value by receiving a file constant passed as an argument, by receiving a file constant as the value of a function, or by simple assignment. A file variable is declared with the VARIABLE attribute. For example:
DECLARE G FILE; DECLARE F FILE; DECLARE V FILE VARIABLE; V=F; ... V=G;
In this example, F and G are file constants, each of which has an associated file control block. V is a file variable that can be assigned file values. After the first assignment, both F and V designate the same file control block. Any operation performed on V is equivalent to the same operation performed on F. After the second assignment, any operation performed on V is equivalent to the same operation performed on G, because both V and G designate the same file control block.
A file name used as a parameter is a file variable and designates the same file control block as its corresponding argument.
To determine the system name of a file to match with a PL/I file, Open PL/I uses the name specified in the TITLE option of the OPEN statement. If the TITLE option is omitted, Open PL/I uses, by default, the name of the file constant or file variable in the PL/I program (shifted to uppercase). You can, instead, use system environment variables to easily specify the system names of files at run-time. The environment variable must be named in this fashion:
LPI_name system-filename
where:
name is the TITLE-specified or default name indicated by the program.
DECLARE DATA2 UPDATE FILE; OPEN FILE(DATA2) /* no title */;
DECLARE FACTS STREAM FILE; OPEN FILE(FACTS) TITLE('Report');
If you do not use environment variables to connect these openings with systems files, the following system names will be assumed for the files: DATA2 and Report.
Instead, prior to running the application, you could set environment variables as follows, causing the specified system files to be used. (Any directories used in the path names must exist.)
setenv LPI_DATA2 /dir1/dir2/master.data setenv LPI_Report /doc/reports/deptA/week23.rep
In the second example, LPI_Report was used rather than LPI_FACTS, because of the TITLE option in that file's OPEN statement.
Open PL/I provides two types of Input/Output processing: stream I/O and record I/O. Each type of I/O has its own statements, and each type operates on its own kind of files. Open PL/I can process more than 32, 767 records per file and supports UNIX named pipes, which enables the reading and writing of massive data sets — greater than 2 GB — something not normally permitted in UNIX I/O.
A stream file is a sequence of characters organized into lines and pages. When reading or writing a file using stream I/O, the data is treated as if it formed a continuous stream of ASCII characters. Stream files are written by PUT statements and are read by GET statements.
A record file is a set of discrete records that are accessible either sequentially or by keys. When reading or writing a file using record I/O, only one record is processed upon the execution of the I/O statement. Record files are read and written by READ, WRITE, REWRITE, and DELETE statements.
The following sections provide detailed information on the two types of input and output processing available through Open PL/I: stream I/O and record I/O.
Stream I/O treats data in the external file as a stream of ASCII characters. In a stream I/O operation, a list of program variables is associated with actual input or output fields of data.
Two forms of stream I/O statements exist:
In both list-directed and edit-directed stream I/O, the files are written by the PUT statement and are read by the GET statement. In edit-directed stream I/O, data is transmitted to or from a stream file under the control of a format-list. In list-directed stream I/O, data is transmitted to and from the stream file without a format-list. In edit-directed stream I/O, format-lists can be part of the GET or PUT statement or can be given by a FORMAT statement.
Execution of a GET or PUT statement transmits data from or to the current line of a stream file and may not consume or produce an entire line of the stream file. Several PUT statements can be used to build a given line, or a single PUT statement can be used to output several lines. Similarly, several GET statements can read values from a given line, or a single GET statement can be used to read one or more lines. Lines read from a disk file are not modified by Open PL/I in any way; however, lines read from all other devices have trailing blanks removed and have one blank appended to the end of each line that is read by a GET statement. This blank ensures that a field typed at the beginning of a line is not appended to a field typed at the end of the previous line.
Each stream file has an associated line size that is determined when the file is opened. Lines of an output file contain n characters, where n is the line size of the file. (For more information, see the discussion of the LINESIZE option in the section Stream File Attributes.) A shorter line can be created by using the SKIP option on a PUT statement, as shown in the following example of a list-directed stream I/O statement. The shorter lines are padded to the right with blanks to obtain a length of n characters. For example:
PUT FILE(F) SKIP LIST(A,B,C); PUT FILE(F) SKIP;
In this example, the current line (consisting of data previously output) is output and one or more new lines containing the values of A, B, and C are created. The second PUT statement forces the last line containing A, B, and C to be output and starts a new line. The SKIP option is always executed before any new data is transmitted.
On input, each line can be of any length up to the value of the line size. Execution of a GET statement reads from the current line until a new line is reached, the new line is ignored, and execution continues reading values and lines until the list of variables has been read. A SKIP option can be used to force a new line to be read prior to reading any values, as shown in the following example.
GET FILE(F) LIST(A,B,C); GET FILE(F) LIST(D); GET FILE(F) SKIP LIST(X,Y);
In the previous example, A, B, and C are read from the current line or from as many lines as are necessary. D is read from the same line as C, unless C happened to be the last value on its line. The SKIP option skips to a new line and consequently ignores any values remaining on the line after the value received by D. X and Y are read from the line that is current after the SKIP option, as well as any additional, necessary lines.
The PAGE option can be used in a PUT statement to begin a new page prior to transmitting any values, as shown in the following example.
PUT FILE(F) PAGE LIST(A,B,C);
For a complete discussion of GET, PUT, and FORMAT statements, see the chapter Statements.
Note: Standard PL/I, in a stream file, does not provide a way to read a variable-length input line from the current position to a newline indicator. Open PL/I provides two nonstandard methods to read all characters from current position to new line into a character varying variable: a READ statement (described in the section READ) and an edit-directed GET statement. To read a variable-length line with a GET statement, you must use an A-format without a field width. (for more information, see the section A-Format.)
Values transmitted by list-directed stream I/O are separated by blanks or commas on input and by blanks on output. Each value is transmitted in a readable format determined by the value's data type.
In a GET LIST operation, Open PL/I automatically converts ASCII input data to the data types of the variables specified in the GET LIST statement. In a PUT LIST operation, Open PL/I converts a computational expression to its ASCII equivalent for output.
The following example of simple terminal output demonstrates list-directed stream I/O:
PUT LIST(A,B);
In this example, if A is an integer declared fixed binary whose current value is -75, and B is a character-string declared character(5) whose current value is HAT , the example produces:
, the example produces:

in the current output line of file F. The field 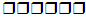 -75 is produced by converting the fixed binary(15) integer to a character-string. The many blanks allow for the maximum possible value, plus sign and decimal point and leading 0 for fractional values, as explained in the section Arithmetic to Character-String Conversion. A single blank separates the value of A from the value of B. The last blank separates B from the next field.
-75 is produced by converting the fixed binary(15) integer to a character-string. The many blanks allow for the maximum possible value, plus sign and decimal point and leading 0 for fractional values, as explained in the section Arithmetic to Character-String Conversion. A single blank separates the value of A from the value of B. The last blank separates B from the next field.
For input, list-directed I/O considers each blank or comma as a field terminator. Excess commas are not allowed. Excess blanks within a field to be assigned to an arithmetic variable are ignored. Such fields must simply contain a valid constant, as could be written in the text of a program.
A field to be assigned to a character-string variable may contain a character-string constant, as written in the text of a program, or it may contain a sequence of any characters. In the latter case, the sequence begins with the first non-blank character in the field and ends with the character immediately preceding the next comma or blank, as shown in the following example of a GET LIST operation. Note that character sequences containing blanks or commas that are to be treated as a unit must be enclosed in single quotation marks ("). For example:
GET FILE(F) LIST(A,B);
In this example, if A is fixed binary(15) and B is character(5), the following lines have the indicated effect on the values of A and B.
| Line | A | B |
|---|---|---|
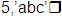 |
5 |  |
 |
-4 5 |  |
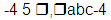 |
-4 5 | abc-4 |
Data-directed stream I/O is similar to list-directed stream I/O. The difference is that with data-directed stream I/O, the actual Open PL/I program names of the data values are included in the stream file along with the values. For example, if your program contains the structure:
DECLARE 1 STRUC,
2 NUM(2) FIXED BIN(15) INIT(255,-432),
2 TEXT CHAR(4) INIT('abcd');
and outputs this data with a PUT DATA statement, the characters emitted for STRUC would be:
STRUC.NUM(1) 255 STRUC.NUM(2)= -432 STRUC.TEXT='abcd' ;
Each data value is preceded by the fully-qualified and specifically subscripted PL/I program name of that data value, as shown. The values themselves are formatted as they would be by a PUT LIST statement, except that character values are always enclosed in quotes.
Values transmitted by edit-directed stream I/O are transmitted into fixed-length fields whose length and content are controlled by data-formats. Data-formats specifically control the type of conversion to be performed and the number of characters or digits in an input or output field. Each data-format corresponds to an element of the GET or PUT statement's value list and causes that value to be converted and transmitted. For example:
PUT FILE(F) EDIT(A,B) (F(7,2),A(6));
In this example, if A is declared fixed binary(15) and has a current value of -45, and B is declared character(4) and has a current value of HAT , the following is written into the current line of file F.
, the following is written into the current line of file F.

Control formats can be used to force new lines and skip parts of lines, as shown in the next example. If there are more format items than values to be transmitted in the statement's I/O list, the extra format items are ignored. For example:
PUT FILE(F) EDIT(A,B) (X(3),F(7,2),SKIP,X(4),A(6),SKIP);
Using the same values of A and B as in the previous example, the above statement produces the following:

In this example, the first line is placed at the end of the current line, and the second line starts a new output line. The PUT statement does not start another new line, because B was the last item output; hence, the PUT statement terminated before the second SKIP was executed.
Edit-directed input requires that each input line be described precisely by the controlling format. If the current input line contains fewer characters than are required to satisfy the format, additional lines are read until the format is satisfied, as shown in the following example.
GET FILE(F) EDIT (X) (A(80));
In this example, if X is declared as character(100) and the current line contains only 60 characters, the 60 characters are read, a new line is read, processing advances to the next line, and 20 additional characters are read from that line. The 80 characters thus read are then assigned to X, and 20 blanks are used to pad the value of X on the right.
If a terminal device is opened as a stream file, the file is unlike any other stream file in the following respects:
The following attributes are appropriate for use with stream files. Some may be used in either the DECLARE statement for the file constant or in the OPEN statement, others only in the OPEN statement.
| Attribute | Permitted in Specification |
|---|---|
| STREAM | DECLARE or OPEN |
| INPUT | DECLARE or OPEN |
| OUTPUT | DECLARE or OPEN |
| DECLARE or OPEN | |
| LINESIZE | OPEN |
| PAGESIZE | OPEN |
| TITLE | OPEN |
The use of PRINT implies STREAM OUTPUT. If neither INPUT, OUTPUT, nor PRINT is specified, INPUT is assumed. LINESIZE and PAGESIZE can be used only for PRINT files. If neither STREAM nor RECORD is specified, the default is STREAM. (See the section Record I/O.) STREAM and RECORD are mutually exclusive, as are INPUT and OUTPUT. If attributes are specified both in the DECLARE statement and the OPEN statement for a file, the attributes used are the combination of those in the two statements. The combination may include only one of each mutually exclusive set.
The TITLE option is used to associate a file as declared in the PL/I program with a file or device as known to the operating system. In the following examples of OPEN statements, the quoted text in the TITLE options specifies the system filename or device name to be used in I/O operations with the opening of the PL/I file indicated by the FILE option. If the TITLE option is not specified in an OPEN statement, the declared name of the file constant is used as the default title.
OPEN FILE(F) OUTPUT TITLE('thedata');
OPEN FILE(TTY) TITLE('CONSOLE')
STREAM INPUT;
OPEN FILE(PTR) TITLE('LPT1')
STREAM OUTPUT PRINT LINESIZE(132)
PAGESIZE(60);
OPEN FILE(MSG_FILE) INPUT;
/* The default title is 'MSG_FILE' */
The LINESIZE option is used in an OPEN statement to specify the maximum number of characters that can be output in a single line for a STREAM file. If no line size is specified, a default line size is assumed. For more information on LINESIZE, see the section PUT Statement.
The LINESIZE option can appear in the OPEN statement only and is valid only with STREAM OUTPUT files. During output, a newline will be inserted whenever the column position equals (LINESIZE+1). The SKIP or LINE options with a PUT statement cause a newline character to be inserted and the column position to be reset. The COLUMN format with a PUT EDIT statement may cause a newline to be inserted.
The default may vary according to the file name or device. In Open PL/I, the default value of the LINESIZE option is 120.
The PAGESIZE option is used in an OPEN statement to specify the maximum number of lines that can be written to a print file without signaling the ENDPAGE condition. If no page size is specified, a default page size is supplied. In Open PL/I, the default value of the PAGESIZE option is 60.
If a GET or PUT statement is executed on a file that has not been opened, the file is implicitly opened as a STREAM file using the declared name of the file constant as the title. A file so opened by a GET statement is opened as an INPUT file, one so opened by a PUT statement is opened as an OUTPUT file.
You can add text to any existing stream file (any ASCII file) by using the -APPEND option in the TITLE option of the OPEN statement. Thus, if the file you wish to append to is named "logfile," open it with the following TITLE option:
TITLE('logfile -APPEND')
Any subsequent PUT statements to this file simply append their output to the end of the file. (See the section TITLE Options.)
An output stream file opened with the PRINT attribute indicates that the file is a print file. When a file is declared as a print file, the LINESIZE and PAGESIZE options may be specified at file opening to designate the maximum width of an output line and the maximum number of lines per page. The current line number and current page number of the print file can also be accessed using the PAGENO and LINENO built-in functions.
The LINENO built-in function allows you to access the current line number of an output stream file opened with the PRINT attribute. Each time a line is written to the output stream, the line number is incremented by one. Each new line is initially positioned so that the next item is written to column 1 of the line.
The PAGENO built-in function lets you read the current page number of an output stream file opened with the PRINT attribute. The current page number can be set using the PAGENO pseudo-variable. The ENDPAGE condition is signaled when the line to be written has a line number that is the page size plus one, or when a SKIP option positions the file to (or past) page size + 1.
Each time a new page is written, the line number is reset to one and the page number is incremented by one.
If an ON-unit for the ENDPAGE condition does not write a new page, the line number is allowed to increase indefinitely until a new page is written. The ENDPAGE condition is signaled only when the line to be written has a line number that is one greater than the page size.
A new page is written only by a PAGE option of a PUT statement, by a PAGE format-item, and by the default ON-unit for the ENDPAGE condition.
In Open PL/I, tab stops are set every eight columns for a stream file that has the PRINT attribute.
In Record I/O, file data is treated in terms of records. Record files are used with the READ, WRITE, REWRITE, and DELETE statements. Execution of one of these statements transmits one record to or from the file and updates the current position of the file.
A record is a contiguous set of bytes of data in the file. The records of the file may all be of the same fixed length, as specified when the file is created, or they may be of varying lengths. Certain files with variable-length records require that a maximum length be specified when the file is created.
The data bytes that comprise a record file may be ASCII characters, but they may also be any kind of binary data, including being paired as halfwords, grouped as binary fullwords or double words, grouped as packed-decimal strings, or considered as bit fields of any length.
Record files may be keyed or not. If a record file does not have keys, its records can be accessed only in sequential order as they exist in the file, one after the other from the beginning of the file to the end. Open PL/I supports two keyed access methods: indexed (VSAM) I/O, which is based on character-string keys, and relative record I/O, which is based on integer record numbers.
The following attributes are appropriate for use with record files. Some may be used in either the DECLARE statement for the file constant or in the OPEN statement, others only in the OPEN statement. Some attributes, if present, imply the presence of certain others.
| Attribute | Permitted in Specification | Implied |
|---|---|---|
| RECORD | DECLARE or OPEN | |
| INPUT | DECLARE or OPEN | |
| OUTPUT | DECLARE or OPEN | |
| UPDATE | DECLARE or OPEN | RECORD |
| SEQUENTIAL | DECLARE or OPEN | RECORD |
| KEYED | DECLARE or OPEN | RECORD |
| DIRECT | DECLARE or OPEN | RECORD KEYED |
| ENVIRONMENT | DECLARE | |
| TITLE | OPEN |
If neither INPUT, OUTPUT, nor UPDATE is specified, INPUT is assumed. If neither SEQUENTIAL nor DIRECT is specified, SEQUENTIAL is assumed. If neither STREAM nor RECORD is specified, the default is STREAM. (See the section Stream I/O.) The following sets of attributes are mutually exclusive:
If attributes are specified both in the DECLARE statement and the OPEN statement for a file, the attributes used are the combination of those in the two statements. The combination may include only one of each mutually exclusive set.
The TITLE option is used to associate a file as declared in the PL/I program with a file as known to the operating system. In the following examples of OPEN statements, the quoted text in the TITLE options specifies the system filename to be used in I/O operations with this opening of the PL/I file indicated by the FILE option. If the TITLE option is not specified in an OPEN statement, the declared name of the file constant is used as the default title.
OPEN FILE(F) RECORD OUTPUT TITLE('thedata');
OPEN FILE(F) RECORD INPUT; /* The default title is 'F' */
If a READ, WRITE, REWRITE, or DELETE statement is executed on a file that has not been opened, the file is implicitly opened as a RECORD file using the declared name of the file constant as the title. The attributes assigned to the file implicitly opened depend on the I/O statement used, as indicated below:
| Record I/O Statement | Assigned Attributes |
|---|---|
| READ | RECORD INPUT |
| WRITE | RECORD OUTPUT |
| REWRITE | RECORD UPDATE |
| DELETE | RECORD UPDATE |
Record input and output operations are restricted to files opened with certain attributes. These restrictions are shown in the following table:
| File Attributes | Permitted I/O Operations |
|---|---|
| INPUT | READ |
| OUTPUT | WRITE |
| UPDATE | READ, WRITE, REWRITE, DELETE |
If a file opened for INPUT or UPDATE does not exist, an error is signaled.
If a file opened for OUTPUT does not exist, a file is created. If the file has been opened as DIRECT or KEYED SEQUENTIAL, a keyed file is created; otherwise, a non-keyed file is created.
If a file opened for OUTPUT already exists, it is deleted and a new file is created.
However, if the -APPEND option is specified in opening the file, an existing file can be opened for OUTPUT. You can add records to an existing record file by using the -APPEND option in the TITLE option of the OPEN statement. Thus, if the file you wish to append to is named "logfile," open it with the following TITLE option:
TITLE ('logfile -APPEND')
Any subsequent WRITE statements to this file simply append their output to the end of the file. (See the section TITLE Options.)
A REWRITE statement replaces an existing record in an UPDATE file with a new record. A DELETE statement basically removes an existing record from an UPDATE file. A WRITE to an existing record and a READ from a nonexistent record are not allowed. A WRITE to a record past EOF will append the record to the end of the file. A DELETE or REWRITE of a nonexistent record signals a KEY condition. (For further information, see the description of KEY in the section ON.)
Record I/O statements copy the storage of a variable to or from a record in a file (except in the case of READ operations using locate mode I/O, see below).
No conversion is performed and no check is made to ensure that the data being read is of the proper type to store into the variable. The variables used in INTO or FROM options cannot be unaligned bit strings or structures consisting entirely of unaligned bit strings, because such variables normally share a portion of their storage with other members of the same array or structure. Also, an expression cannot be used in a FROM or INTO option.
Note: Structures with the UNION attribute cannot be used as variables in READ, WRITE, PUT, and GET statements.
READ operations can be performed in two "modes": move mode and locate mode. A READ statement that specifies the INTO option causes the input data to be stored directly into the variable referenced by the INTO option. This is called a "move mode" READ. A READ statement that specifies the SET option instead of the INTO option causes the input data to be stored in an unnamed storage buffer and causes the address of this buffer to be assigned to the pointer variable referenced by the SET option. This is called a "locate mode" READ.
A complete discussion of record I/O statements is found in the chapter Statements.
READ FILE(CUSTOMERS) KEY(CUST_ID) INTO(CUST_RECORD); PUT SKIP LIST(CUST_RECORD.NAME); READ FILE(CUSTOMERS) KEY(CUST_ID) SET(CPTR); PUT SKIP LIST(CPTR->BASED_RECORD.NAME);
A record file without keys is called a consecutive file. The records of such a file can be read only in the same sequential order in which they were written. Thus, a consecutive file can be read only one record after the other, starting with the first record in the file. A record of a consecutive file can be rewritten, but only immediately after it has been read.
A consecutive file is declared by including the CONSECUTIVE option of the ENVIRONMENT attribute. For example,
DECLARE ULOG RECORD OUTPUT FILE
ENVIRONMENT(CONSECUTIVE RECSIZE(130));
In this example the RECSIZE option causes all records to be of length 130 bytes. If RECSIZE is omitted, variable length records may be written. In the latter case, there is no information automatically recorded in the file to indicate the length of the records. A program reading the file must have the ability to know how many bytes to read with each READ statement.
CONFILE: PROCEDURE OPTIONS(MAIN);
DECLARE TEST RECORD OUTPUT FILE ENV(CONSECUTIVE);
DECLARE REC1 CHAR(5) INIT('AAAAA');
DECLARE REC2 CHAR(10) INIT('BEEBBBBBBB');
OPEN FILE(TEST) TITLE('testdata');
WRITE FILE(TEST) FROM(REC1);
WRITE FILE(TEST) FROM(REC2);
WRITE FILE(TEST) FROM(REC1);
CLOSE FILE(TEST);
END CONFILE;
The file testdata resulting from this program will contain the following 20 bytes:
AAAAABBBBBBBBBBAAAAA
Note: Open PL/I has an older method of accomplishing the same thing. It is done by using the TITLE option of the OPEN statement rather than the ENVIRONMENT attribute of the DECLARE statement. The following illustrates the old method.
DECLARE RECORD TEST OUTPUT FILE;
OPEN FILE (TEST) TITLE ('testfile -SAM');(See the section TITLE Options.)
Open PL/I's indexed I/O, also called VSAM (Virtual Storage Access Method), involves the use of character-string keys that are stored in the records of the file. Every record has a key, and the keys are ordered lexicographically in an index that is associated with the file. The records can be accessed randomly by specifying the key of the desired record, or they can be accessed sequentially according to the order of the keys, or they can be accessed by a combination of these methods, as illustrated in the following table:.
| File Attributes | Permitted Access |
|---|---|
| SEQUENTIAL | SEQUENTIAL only |
| DIRECT | KEYED only |
| KEYED SEQUENTIAL | SEQUENTIAL and/or KEYED in combination |
An INDEXED (equivalently, VSAM) file is declared by including either the INDEXED or the VSAM option of the ENVIRONMENT attribute. For example,
DECLARE MASTER RECORD OUTPUT FILE ENVIRONMENT(VSAM KEYLOC(1) KEYLENGTH(12) RECSIZE(130));
The KEYLOC option specifies the byte position of the first byte of the key in the records, counting the first byte as KEYLOC(1). The KEYLENGTH option specifies the number of characters in the key. RECSIZE specifies the record length or, in the case of a file of variable-length records, it specifies the maximum record length.
Actually, it is necessary to specify RECSIZE, KEYLOC, and KEYLENGTH for a file only when it is created. Programs that read or update an existing indexed file do not need to include these options, although they may. Open PL/I can determine these characteristics from an existing file. If you are using full IBM mode, file header information is used when opening a VSAM file for output, rather than requiring you to specify RECSIZE, KEYLOC, or KEYLENGTH with the ENVIRONMENT attribute.
There are a number of options that can be specified with the ENVIRONMENT attribute. These options are described in Table 1-5. This table also lists a number of options that are not needed or not supported in Open PL/I, but which a user may expect to find based on experience with other compilers.
| Option | |
|---|---|
| Description | |
| ASCII | The ASCII option is assumed in Open PL/I. |
| BKWD | Specifies backward processing for indexed files read in the SEQUENTIAL mode; that is, sequential processing will start with the current record (or last, by default) in the file and proceed to previous records. |
| BUFFERS | The BUFFERS option is not needed in Open PL/I. If it is used, the Compiler ignores it. |
| BUFOFF | The BUFOFF option is not needed in Open PL/I. If it is used, the Compiler ignores it. |
| BUFND | The BUFND option is not needed in Open PL/I. If it is used, the Compiler ignores it. |
| BUFNI | The BUFNI option is not needed in Open PL/I. If it is used, the Compiler ignores it. |
| BUFSP | The BUFSP option is not needed in Open PL/I. If it is used, the Compiler ignores it. |
| CONSECUTIVE | Specifies a file with consecutive organization. For related information, see the description of the -defext compiler option in your Open PL/I User's Guide. |
| CTLASA | The CTLASA option is ignored. |
| CTL360 | The CTL360 option is not implemented in Open PL/I. If it is used, the Compiler issues a warning. |
| F | FB | FS | FBS | Specifies record format, where F = fixed length, B = blocked, and S = standard. Open PL/I treats any such specification as though it were F alone — fixed length. |
| GENKEY | Specifies a generic key, a character string that is a prefix of a key. A READ with a KEY clause returns the first record whose key is greater than or equal to the string specified by the KEY clause. A subsequent sequential READ (no KEY clause) will return the next record greater than the current record. |
| INDEXAREA(n) | The INDEXAREA option is not needed in Open PL/I. If it is used, the Compiler ignores it. |
| INDEXED | Specifies a file with indexed organization. For related information, see the description of the -defext compiler option in your Open PL/I User's Guide. |
| KEYLENGTH(n) | Specifies the length, n, of the embedded key for indexed files. KEYLENGTH can be specified only when INDEXED or VSAM is specified. |
| KEYLOC(n) | Specifies the starting location of an embedded key in a record. n must be within the limits:
1 ≥ n ≥ recordsize – keylength + 1. The default KEYLOC value is 1. KEYLOC can be specified only when INDEXED or VSAM is specified. Note: Be sure that KEYLOC considers the 2-byte prefix generated by specification of the SCALARVARYING option. |
| LEAVE | The LEAVE option is not needed in Open PL/I. If it is used, the Compiler ignores it. |
| MINRECSIZE(n) | Specifies the minimum record length, n. n must be an integer. This option allows for better disk space utilization. The MINRECSIZE option is required with V (variable-length) record formats. It is ignored for F (fixed-length) record formats. The values specified for the KEYLOC and KEYLENGTH options must be within the value specified by the MINRECSIZE option. For more information on the MINRECSIZE option, see below. |
| NCP(n) | The NCP option is not applicable in Open PL/I. Open PL/I treats INDEXED files the same as VSAM files. |
| NOWRITE | The NOWRITE option is not needed in Open PL/I. If it is used, the Compiler ignores it. |
| PASSWORD(pwd) | The PASSWORD option is not implemented in Open PL/I. If it is used, the Compiler issues a warning. |
| RECSIZE(n) | Specifies the maximum record length, n. n must be an integer. |
| REGIONAL(1 | 2 | 3) | The REGIONAL(1) option specifies files whose records are identified by their region numbers.
The REGIONAL(2) and REGIONAL(3) options are not implemented in Open PL/I. If they are used, the Compiler flags it as an error. |
| REUSE | The REUSE option specifies that an OUTPUT file associated with a VSAM data set is to be used as a work file. . |
| SCALARVARYING | Used for the input and output of varying length records. SCALARVARYING enables the recognition of a two-byte prefix that specifies the current length of the records. Note: Be sure that KEYLOC considers the 2-byte prefix generated by specification of the SCALARVARYING option. |
| SIS | The SIS option is not needed in Open PL/I. If it is used, the Compiler ignores it. |
| SKIP | The SKIP option is not needed in Open PL/I. If it is used, the Compiler ignores it. |
| TP(MIR) | The TP(MIR) option is not implemented in Open PL/I. If it is used, the Compiler flags it as an error. |
| TRKOFL | The TRKOFL option is not needed in Open PL/I. If it is used, the Compiler ignores it. |
| U | D | DB | Specifies record format. Open PL/I treats any such specification as though it were F – fixed length. |
| V | VB | VS | VBS | Specifies record format, where V = variable length, B = blocked, and S = spanned. Open PL/I treats any such specification as though it were V. |
| VSAM | Specifies files organized for the virtual storage access method (VSAM). For related information, see the description of the -defext compiler option in your Open PL/1 User's Guide. |
A random access read of a record in an indexed (VSAM) file opened with the INPUT or UPDATE attribute is accomplished by a READ statement that includes the KEY option. For example,
READ FILE(PARTS) INTO(PART_REC) KEY(PART_NUM);
A sequential read reads the next record of the file after the last one read — using the key ordering — or the first record of the file, if no record has previously been read. For a sequential READ statement, the KEY option is omitted.
If a record has previously been read from a file opened with the UPDATE attribute, and no other intervening I/O operation has been performed, a REWRITE without key may be executed. In this case, the previously read record is overwritten with the new value. For example,
READ FILE(PARTS) INTO(PART_REC) KEY(PART_NUM); PART_REC = NEW VALUE; REWRITE FILE(PARTS) FROM(PART_REC);
However, a record of an indexed file can be randomly updated by specifying the KEYFROM option in the REWRITE statement. For example,
REWRITE FILE(PARTS) FROM(PART_REC) KEYFROM('12XJ04');
If an indexed file has been opened with the OUTPUT or UPDATE attribute, a WRITE statement using the KEYFROM option can be used to add new records to the file. The WRITE statement without KEYFROM is used to sequentially add new records to a file.
The DELETE statement can be used to remove records from an indexed file opened with the UPDATE attribute. The KEY option must be used to delete a record.
All keys used in an indexed (VSAM) file must by of type CHARACTER. If a KEY or KEYFROM option references a value that is not of type CHARACTER, the value is converted to CHARACTER before the I/O operation begins. Note that keys of type PICTURE are converted to CHARACTER without any actual change in the key contents. (See the chapter Data Type Conversions.)
An indexed (VSAM) file can have either fixed-length or variable-length records. The records are fixed-length if the F option is used with the ENVIRONMENT attribute when the file is created; they are variable-length if the V option is used. (See Table 1-5.) If neither F nor V is specified, F is assumed.
In a fixed-length record file, all records must have the same length, which is the length specified by the RECSIZE option of the ENVIRONMENT attribute when the file was created. For a variable-length record file, RECSIZE specifies the maximum record length that is permitted in the file. The MINRECSIZE option must also be specified for a variable-length record file. This value specifies the minimum length that all records in the file must have. The keys of the file must be contained within this minimum portion of the file.
The SCALARVARYING option specifies that there is a two-byte prefix on all records in the data file. A user must take this into account when specifying the KEYLOC value. The KEYLOC value is the absolute byte position of the record starting at 1. This option can be used on either F or V record formats. It allows for more general use of character varying records in I/O statements, although character records can also be transmitted. When a character varying item is used in a WRITE or REWRITE statement, the two-byte prefix is retained with the record as it gets written out to the data file, if the SCALARVARYING option is set. Without the SCALARVARYING option, the prefix is not written; in this case, the remainder of the record is undefined beyond its current length. When a character record is written, a prefix will be added if SCALARVARYING option is set. The SCALARVARYING option lets you write and read records smaller then your max record size, without getting the RECORD condition. It also is useful when doing locate mode I/O.
When setting KEYLOC, it is very important to "compensate" for the two-byte prefix when the SCALARVARYING option is used.
The use of V type records provide a way to transmit partial records. Open PL/I does not require control bytes in the record for this support. The run-time system will automatically retain information concerning the number of bytes transmitted. Since no control information is needed in the record, the user should not change KEYLOC based on the record type. Only the SCALARVARYING option has impact on the KEYLOC location.
Open PL/I allows you to choose among different I/O subsystems for support of indexed (VSAM) files. No source changes are required for this choice. There are load time (Idpl1) options (-ofm, -sfs, or -cisam) that can be used. For the list of I/O subsystems supported with your Open PL/I product, see the Open PL/I User's Guide and/or Release Notes.
Although the PL/I language does not provide a mechanism by which multiple keys can be specified for a file, Open PL/I does provide a means for accessing data via multiple keys. After an indexed file has been created using one key (which is called the primary key), you can use the utility Ipivsam to add additional indexes (that is, keys) to the file. In the PL/I program each different key version of the data must be declared as a separate file. However, all of these declared files can actually be referencing the same set of data. For example,
DECLARE EMPFILE1 RECORD UPDATE FILE
ENV(VSAM KEYLOC(1) KEYLENGTH(6) RECSIZE(145));
DECLARE EMPFILE2 RECORD UPDATE FILE
ENV(VSAM KEYLOC(31) KEYLENGTH(3) RECSIZE(145) GENKEY);
DECLARE 1 EMP_
2 EMP_ID (CHAR(6),
2 NAME (CHAR(24),
2 DEPARTMT (CHAR(3),
...
OPEN FILE(CUSTFILE1) TITLE('employee');
OPEN FILE(CUSTFILE2) TITLE('employee');
/* same file, different key */
The Ipivsam utility can be used to create an indexed (VSAM) file, to add an index, to eliminate an index, or to display information about an indexed file. (For more information, see your Open PL/I User's Guide.)
The following example program illustrates the use of the ENVIRONMENT variable and its options for I/O on a file with VSAM organization.
/* Example of VSAM I/O */
TEST: PROCEDURE OPTIONS(MAIN);
%REPLACE TRUE BY '1'B; %REPLACE FALSE BY '0'B;
DECLARE DB FILE ENV(VSAM KEYLOC(21) KEYLENGTH(120) RECSIZE(244));
DECLARE DBG FILE ENV(INDEXED GENKEY KEYLOC(21)
KEYLENGTH(120) RECSIZE(244));
DECLARE 1 DB_RECORD,
2 HEADER CHAR(20),
2 DBKEY CHAR(120),
2 STUFF CHAR(100),
2 NUMBER FIXED BIN(31);
DECLARE I FIXED BIN(31);
DECLARE CS CHAR(26) STATIC
INIT('THEQUICKBROWNFXJMPSVLAZYDG');
DECLARE C(26) CHAR DEFINED(CS);
DECLARE LETTERS CHAR(30);
/* CREATE DB */
OPEN FILE(DB) RECORD KEYED SEQUENTIAL OUTPUT
TITLE('MYFILE1');
HEADER = 'DATA RECORD HEADER';
STUFF = COPY('ABCDE',20);
DO I = 1 TO 26;
NUMBER = I;
DBKEY = '@'||C(I) ||COPY('@',118);
WRITE FILE(DB) FROM(DB_RECORD) KEYFROM(DBKEY);
END;
CLOSE FILE(DB);
/* TRY A GENERIC READ THEN MOVE SEQUENTIALLY THRU THE FILE */
OPEN FILE(DBG) RECORD KEYED SEQUENTIAL INPUT
TITLE('MYFILE1');
ON ENDFILE(DBG) GOTO EXIT_1;
READ FILE(DBG) KEY('@') INTO(DB_RECORD);
LETTERS = SUBSTR(DBKEY,2,1);
DO WHILE(TRUE);
READ FILE(DBG) INTO(DB_RECORD);
LETTERS = TRIM(LETTERS) ||SUBSTR(DBKEY,2,1);
END;
EXIT_1:
CLOSE FILE(DBG);
PUT EDIT(LETTERS)(A);
IF LETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' THEN
PUT SKIP LIST('TEST PASSES');
ELSE PUT SKIP LIST('TEST FAILS');
PUT SKIP;
END TEST;
Open PL/I also provides an I/O method for accessing consecutive files by a numeric key representing the relative record numbers of the records in the file. This is called relative record I/O. It can be used only with files of fixed-length records, and it cannot be used with indexed (VSAM) files.
Relative record I/O files are regarded as keyed files, but the keys are not stored in the file. They are just the ordinal numbers of the records in the file. The keys must be positive integers. Any value used in a KEY or KEYFROM option of an I/O statement must be an integer or be capable of conversion to an integer.
The ENVIRONMENT attribute is not used in the declaration of a relative record I/O file. Instead, such a file is specified by using an extension of the TITLE option of the OPEN statement. The format of this TITLE option is as follows:
TITLE('filename -DAM n')
where n is the length of the records in the file. The length n includes two bytes that are normally added to the beginning of each record. This halfword is used to record special information about the file.(See the section TITLE Options.)
In general, the same set of PL/I I/O operations can be used with relative record I/O files as with indexed files.
A relative record I/O file can be created using an additional extension in the TITLE option, as follows:
TITLE('filename -DAM n -NOSIZE')
The -NOSIZE option indicates that the two-byte special field is not to be added to the data records. If -NOSIZE is specified for a file, the DELETE statement cannot be used with the file. (See the section TITLE Options.)
A REGIONAL(1) file does not have keys recorded in the records. Instead, each record is identified by its region number, which is an unsigned integer. The keys for a REGIONAL(1) file may be character strings consisting only of decimal digits, possibly preceded by leading spaces (which are interpreted as zeros), or the keys can be of integer type.
A REGIONAL(1) file contains data records and dummy records. A dummy record is identified by having a first byte with the hex value FF. Dummy records represent records that have been deleted or whose region numbers have been skipped over when the file was first created. You can also create them explicitly by writing a record whose first byte has the value hex FF. Dummy records are not ignored when the REGIONAL(1) file is read. An Open PL/I program reading a REGIONAL(1) file must be designed to deal with dummy records. You can replace dummy records with valid data records.
You can create a REGIONAL(1) file only by use of DIRECT OUTPUT mode using keyed WRITE statements. The records must be written in ascending region number order, but you may skip over region numbers. When a region number is skipped, a dummy record is written in its place. The KEY condition is raised if you attempt to write records other than in increasing sequence or if you attempt to write a record with a duplicate key.
An existing REGIONAL(1) file can be accessed in SEQUENTIAL INPUT or UPDATE mode, or in DIRECT INPUT or UPDATE mode. (Opening the file in OUTPUT mode causes the existing file to be overwritten.)
If a REGIONAL(1) file is opened for SEQUENTIAL access (INPUT or UP_ DATE), the records are retrieved in ascending order of their region numbers. Dummy records are retrieved as well as valid data records. With SEQUENTIAL INPUT, you can read all records of the file in ascending region number order; with SEQUENTIAL UPDATE, you can so read all records and update those you choose (including changing dummy records to valid data records, and valid data records to dummy records). The rules for sequential READ and REWRITE for REGIONAL(1) are the same as for CONSECUTIVE files.
A REGIONAL(1) file can be opened for INPUT or UPDATE in DIRECT access mode, in which case keyed READ, WRITE, REWRITE, and DELETE statements can be used. READ accesses dummy records as well as valid data records. WRITE and REWRITE are equivalent; either replaces an existing record (data or dummy record) with a replacement record (again, either a data or a dummy record). DELETE converts the record with the specified region number into a dummy record.
/* This program creates and updates a REGIONAL(1) file */
sample: procedure options(main);
declare File1 file environment(regional(1) recsize(20));/*requires -defext
declare Buffer char(20);
declare FirstByte char(1) defined(Buffer);
declare Key char(4) varying;
declare Eof bit;
put skip list('Creating REGIONAL(1) file with records 1, 5 and 9.');
open file(File1) output;
Buffer = copy('1',size(Buffer));
write file (File1) from(Buffer) keyfrom (1);
Buffer = copy('5',size(Buffer));
write file (File1) from(Buffer) keyfrom (5);
Buffer = copy('9',size(Buffer));
write file (File1) from(Buffer) keyfrom (9);
close file(File1);
open file(File1) update;
on endfile(File1) Eof = '1'b1;
Eof '0'b1; /* Initialize */
put skip list('Reading file and updating the even numbered records.');
read file(File1) into(Buffer) keyto(Key);
do while (^Eof);
if unspec(FirstByte) = 'FF'b4 then do; /* dummy record */
if (mod(fixed(Key,15),2) = 0) then do; /* change even number ones *
Buffer = 'rewritten';
rewrite file(File1) from (Buffer); /* rewrite current record */
end;
end;
read file(File1) into (Buffer) keyto(Key);
end;
Eof = '0'b1; /* Reset */
put skip(2) list ('Reading and displaying all records in file.');
Key = '1';
read file(File1) into(Buffer) key(Key); /* direct read */
do while (^Eof);
if unspec(FirstByte) = 'FF'b4 then put skip list(Key,'<dummy record>');
else put skip list(Key,Buffer);
read file(File1) into(Buffer) keyto(Key); /* sequential read */
end;
close file(File1);
put skip;
end sample;
You can compile, link, execute, and display the output of the above sample program with the following commands:
mfplx sample.pl1 -defext -o sample.out sample.out
The output is as follows:
Creating REGIONAL(1) file with records 1, 5 and 9. Reading file and updating the even numbered records. Reading and displaying all records in file. 1 11111111111111111111 2 rewritten 3 <dummy record> 4 rewritten 5 55555555555555555555 6 rewritten 7 <dummy record> 8 rewritten 9 99999999999999999999
Open PL/I supports a number of non-standard TITLE options that can be used to indicate the type of file being opened. These are as follows:
-SAM [n]
-DAM [n]
-NOSIZE
-APPEND [n]
-DELABORT [n]
where n is an integer indicating that the file has fixed-length records of length n bytes.
These options are included in the operand of the TITLE option immediately following the filename and separated from it by one or more spaces, as shown in the following examples:
TITLE('recfile.dat -SAM 80')
TITLE('keyfile -DAM')
The -SAM and -APPEND options can be used with stream files, in which case the length, if specified, is ignored. -SAM is never required for stream files.
-SAM [n] specifies that the file is a consecutive file. If n is specified when the file is created, the file is created with records of fixed length n. The maximum value for n is 131,017 bytes. If n is not specified when the file is created, records written to the file can be of any length and of varying lengths. If -SAM is used when opening a file for OUTPUT, if the file already exists, it is deleted and a new file is created.
-DAM [n] specifies that the file is a relative record I/O file. If n is specified when the file is created, the file is created with records of fixed length n. If n is not specified when the file is created, the file is created as a variable-length record file. If -NOSIZE is not also specified, this length n includes the two bytes that are added as a halfword of length information at the beginning of each record.
-NOSIZE can be used alone or in combination with -DAM [n]. It specifies that the length halfword is not included at the beginning of each record. If -NOSIZE is used without -DAM [n], -DAM is implied.
-APPEND [n] has the same meaning as -SAM, except that when used in opening a file for OUTPUT, it causes an already existing file to be appended to rather than replaced.
-DELABORT causes the file to be deleted when it is closed.
If a file is opened for OUTPUT and none of these TITLE options is specified, and there is no ENVIRONMENT attribute in the file declaration, if the opening is for a DIRECT file, -DAM is assumed, and if the opening is not for a DIRECT file, -SAM is assumed.
Copyright © 2009 Micro Focus (IP) Ltd. All rights reserved.