Analyzing Aggregated HSF Data in .csv Files
You can use the statistics utility program, casfhsf, to output aggregated data from the .csv files created by the Historical Statistics Facility (HSF). casfhsf outputs this data as a comma-separated value file.
You can use the information to review system performance on a regular basis and avoid going through a large volume of data in order to determine if corrective tuning action is required.
Using the casfhsf statistics utility program
From the Enterprise Developer command prompt, launch casfhsf.exe (Windows) or casfhsf32 or casfhsf64, depending on your environment (UNIX).
The following switches are available. A dash may replace the slash, and switches can be upper or lower case.
| Switch | Description |
|---|---|
| /A | Process only cashsf-a.csv. |
| /B | Process only cashsf-b.csv. |
| /C | Process both cashsf-a.csv and cashsf-b.csv (default). |
| /D | Process only backup files cashsf.nnn. |
| /E | Process all files: cashsf-a.csv, cashsf-b.csv, and cashsf.nnn. |
| /G{s} | Aggregate the output into {s} second intervals where {s} = seconds from 1 to 9999. |
| /S[sd,st,ed,et] | Aggregate the output data by the second. Optionally, you can specify a start date (sd), start time (st), end date (ed), and end time (et). Where [sd,st,ed,et] = yyyymmdd,hhmmss,yyyymmdd,hhmmss [3] |
| /M[sd,st,ed,et] | Aggregate the output data by the minute (default if error). Optionally, you can specify a start date (sd), start time (st), end date (ed), and end time (et). Where [sd,st,ed,et] = yyyymmdd,hhmm,yyyymmdd,hhmm [3] |
| /IP | The location of the input files. The default value is the current directory. |
| /OP | The location of the path of the output file. The default value is the current directory.
The output file is called OutFile.csv. |
| R{t}[[,{t}]...] | Response time criteria by specified ID where {t} = seconds to two decimal places. Default is t=1 second. |
| /T | Report transaction IDs by type. |
| /X | Output date and time as separate columns. |
To aggregate certain transactions or programs, you may specify these using parameters in the form:
{type},{id}[[,{type},{id}]...]The parameters are:
- type
- Transaction type:
- CICS= a CICS transaction
- IMS = an IMS transaction
- JCL = a JCL batch job
- WEB = a Web Service
Note: JCLF records do not participate in aggregation processing. - id
- The identifier of the transaction, job, service or program ID to be aggregated. If id is "Auto", this is an alias for CICS Auto install transaction (x'feffffff').
You can specify between zero and five type,id pairs. Each type must be separated from its corresponding id by a comma. If more than one pair is specified, each pair must be separated by a comma.
If no pair is specified, an aggregate of all transactions is accumulated in the first unallocated slot. The default behavior in this case is to aggregate all data in slot one.
An extfh.cfg file is generated in the current directory, if one is not already present, to allow large file inputs.
If no switches or parameters are specified, the utility will ask if you wish to continue using the default values.
- Example (Windows)
-
casfhsf /a /s /ipc:\es\region2\system CICS,ABCD,CICS,WXYZ
This processes cashsf-a.csv in the directory c:\es\region2\system, and aggregates times (in seconds) separately for the CICS transactions ABCD and WXYZ. - Example (Windows)
-
casfhsf /op"c:\Users\All Users\Micro Focus"
Using the input defaults, this processes both cashsf-a.csv and cashsf-b.csv in the current directory, aggregates times in minutes for all transactions and programs, and creates the output file in the folder c:\Users\All Users\Micro Focus. - Example (UNIX)
-
casfhsf32 /a /s /ipc:$COBDIR/../mfcobol/es/region2 CICS,ABCD,CICS,WXYZ
This processes cashsf-a.csv in the directory $COBDIR/../mfcobol/es/region2, and aggregates times in seconds separately for the CICS transactions ABCD and WXYZ. - Example (UNIX)
-
casfhsf32 /op"/opt/Micro Focus/logs"
Using the input defaults, this processes both cashsf-a.csv and cashsf-b.csv in the current directory, aggregates times (in minutes) for all transactions and programs, and creates the output file in the folder /opt/Micro Focus/logs.
The Output File
time,TPS,SYS<=,%SYS<=,Latency,min,max,Response,min,max,System,min,max,API,min,max,SQL,min,max,IMS,min,max...After the time field, the rest of the fields occur five times.
| Field | Description |
|---|---|
| time | The time period in minutes (hh:mm format) or seconds (hh:mm:ss format) into which the input monitoring times are aggregated. The format is determined by the /S or /M switch. |
| TPS | The average number of transactions per second or minute. |
| SYS<= | The number of transactions that ran within the time range specified with the /R option or within 1 second if the option was not used. |
| %SYS<= | The percentage of transactions that ran within the time range specified with the /R option or within 1 second if the option was not used. |
| Latency,min,max | The average latency - delay or waiting time - for this time period, and the minimum and maximum latency. |
| Response,min,max | The average time taken for Enterprise Server to respond to the transaction request, and the minimum and maximum response times. |
| System,min,max | The total of the average latency and response times (Latency + Response) , and the minimum and maximum totals of latency plus response time of a particular transaction run. |
| API,min,max | The average time, in milliseconds (ms), spent in CICS API (EXEC CICS statements) for this task, and the minimum and maximum times. |
| SQL,min,max | The average time, in milliseconds (ms), spent in SQL API (EXEC SQL statements) for this task, and the minimum and maximum times. |
| IMS,min,max | The average time, in milliseconds (ms), spent in IMS DL/I API for this task, and the minimum and maximum times. |
There is also a secondary header depending on the parameters supplied to the utility.
If there are no parameters, then all the aggregate values are accumulated under "Everything", and the other four columns are marked as "Unused".
Versions of input files
#HSFVer=03;Custom=xx;CicsFiles=xx;TSQ=xx;TDQ=xx
where xx corresponds to the number of fields for each type, as specified by the ES_HSF_CFG environment variable.
#HSFVer=01 or 02
If you are processing multiple files, casfhsf will only aggregate data from files of the same version as the first file it receives. Other versions are ignored. However, whatever version it processes, the output file OutFile.csv will contain all the fields listed above, with values of zero for any missing fields.
Example
- An input file cashsf-a.csv was created during a short run of a CICS region.
- The following command was executed in the directory containing the input file:
casfhsf /a /m CICS,ACCT
This command processes cashsf-a.csv in the current directory, places the output file in the current directory, and aggregates times by the minute.
- An output file,
OutFile.csv is created. The figure below shows the content viewed in Microsoft Excel:
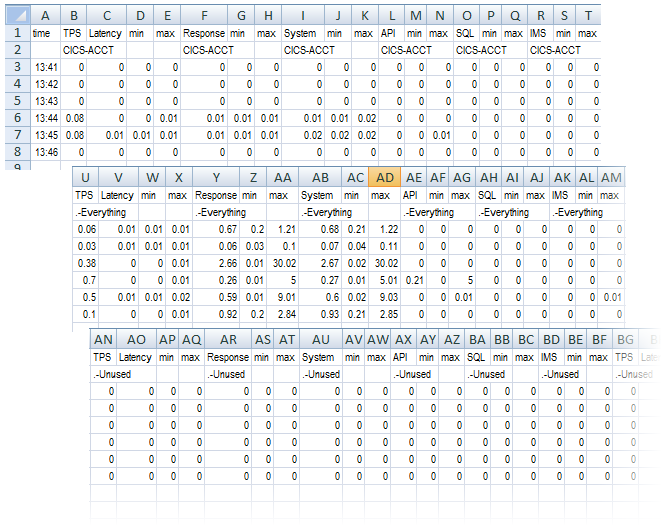
This shows, for example, that at 13:45 aggregated statistics for the CICS transaction ACCT are:- the number of transactions per second is 0.08.
- the average latency is 10 milliseconds (ms).
- the average response time is 10 milliseconds (ms).
- the total (system) response time is 20 milliseconds (ms).